Good Afternoon,
I have recently been working on methods to detect an Information Stealer/Trojan known as Ursnif. The difficulty in detection relies on the use of encrypted Word documents. These documents use an additional encryption pack that comes by default with Office 2007 SP2 or higher. The encryption pack is known as the “High Encryption Pack”. It is used to encrypt the documents in something other than RC6 so simple and automated decryption is more difficult. It also has the added benefit of being extremely fast and not practical to brute force for each variant as the password changes on every email.
The threat actor’s opted to use AES256 for encryption and SHA512 for hashing to make document modifications harder to accomplish without being detected. These are effectively some of the highest settings for encryption and hashing that is available in Microsoft Word. Finally, they purposely implant fake random document summary and summary information into the document to make it appear more legitimate even though it’s malicious. I will go over how I utilized all of these clues in order to detect and block waves of this campaign. As well as an example Yara rule you can implement that targets the specific characteristics of those documents. It should be noted that while the Yara rule is as targeted as possible there is still the potential for false positives in the rare case an end user matches the same exact settings. As such the result should be implemented with caution and approval from your upper management.
This first screenshot shows how the start of the file looks with the magic bytes highlighted. That is the first check the Yara Rule performs. This is also very useful for reducing total number of false positives.

This second screenshot shows the next set of highlighted fields that the Yara rule searches for in order to determine if the document is encrypted. The fields being selected here are also to help target the documents further.

This is the third screenshot it shows additional highlighted fields that are searched for by the Yara rule. If you notice this and the previous screenshot show that the Yara rule’s focus is mainly on the document is encrypted and then secondly verifying the settings preferred by the Ursnif campaign are matched.

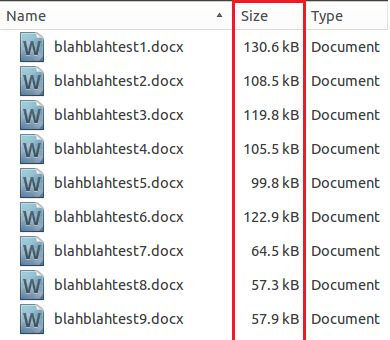
This final screenshot shows the varying sizes which demonstrates why the final check for the documents is based on file size. It is set to be less than 200KB in order to reduce the total number of potential false positives. It should also lower the documents needing to be scanned further to make this rule slightly more efficient.
Analysis of my Thought Process:
The document’s when analyzed in their still encrypted state did not have much data to key off of to detect the documents as potentially malicious. As such when analyzing the files I had to key off of the few things I could that when combined were enough to build a valid and effective signature. For every variant I have had a chance to run this rule against it has detected the sample without issues 100% of the time. Unless the threat actor’s were to change their techniques, which is unlikely since thats the least likely thing to change in campaigns. Then this rule should continue to work without fail. Again the only down side of analyzing the encrypted versus decrypted documents is the potential for false positives.
Final Thoughts:
If your environment is able to detect the passwords in the emails proactively and decrypt the files then there is way more metadata that can be key’d off of. And that data would be much more accurate for detection with even lower possibilities of false positives. As such I would recommend if at all possible to analyze the decrypted version of the documents when possible.
Link to Yara Rule:
https://pastebin.com/W2umDWNF